

After our little JavaScript SEO experiment with setting up hreflang with Google Tag Manager, we decided to run some more tests, in order to analyse how Google deals with changes made to websites with JavaScript, using Google Tag Manager:
- Does Google recognise changes to title tags and meta descriptions implemented with Google Tag Manager?
- Does Google de-index pages set to “noindex” with Google Tag Manager?
- Does Google respect canonical tags added with Google Tag Manager?
- Does Google index pages that are only linked via internal links injected with Google Tag Manager?
- Does Google index URLs that are only linked via JSON-LD markup implemented with Google Tag Manager?
If you’re curious about the answers to these questions, and if you want to know exactly how to set all of this up with Google Tag Manager, keep on reading.
TL;DR – All of these tests worked out fine, but some of the changes took a very long time to show in Google’s results. Jump straight to the conclusions if you’re in a hurry.
Direct access to the different parts of the test:
- Replacing title tags and meta descriptions with Google Tag Manager
- De-indexing pages with “noindex” tags implemented via Google Tag Manager
- Adding canonical tags with Google Tag Manager
- Does Google follow internal links added with Google Tag Manager?
- Does Google index URLs that are only included in JSON-LD scripts added with Google Tag Manager?
Replacing title tags and meta descriptions with Google Tag Manager
The title tag and meta description of the English home page of our company website, https://www.searchviu.com/en/, look like this in the HTML source document of the page:
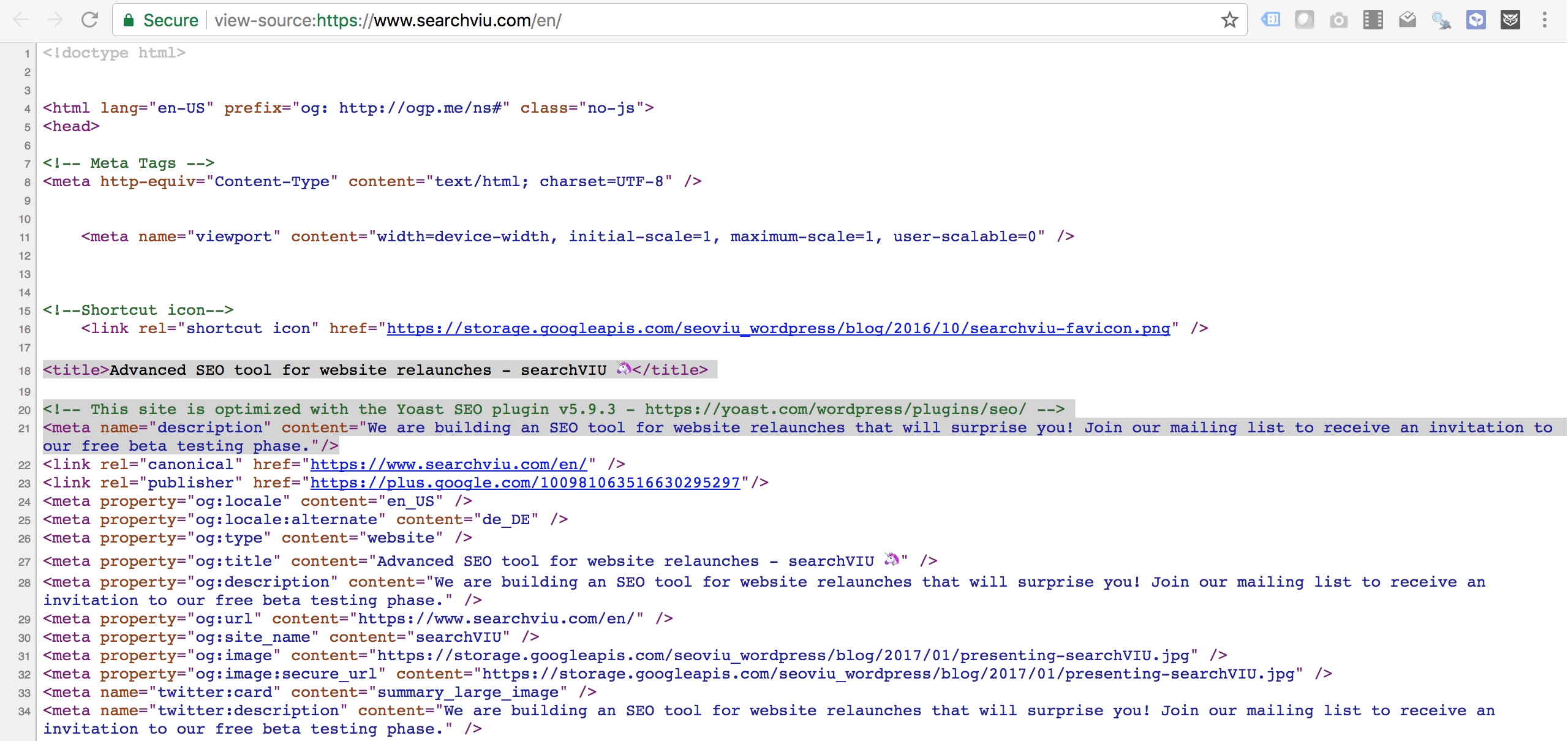
We used the following script in a Custom HTML tag in Google Tag Manager to replace the title tag and meta description, so that a different text shows in the rendered HTML:
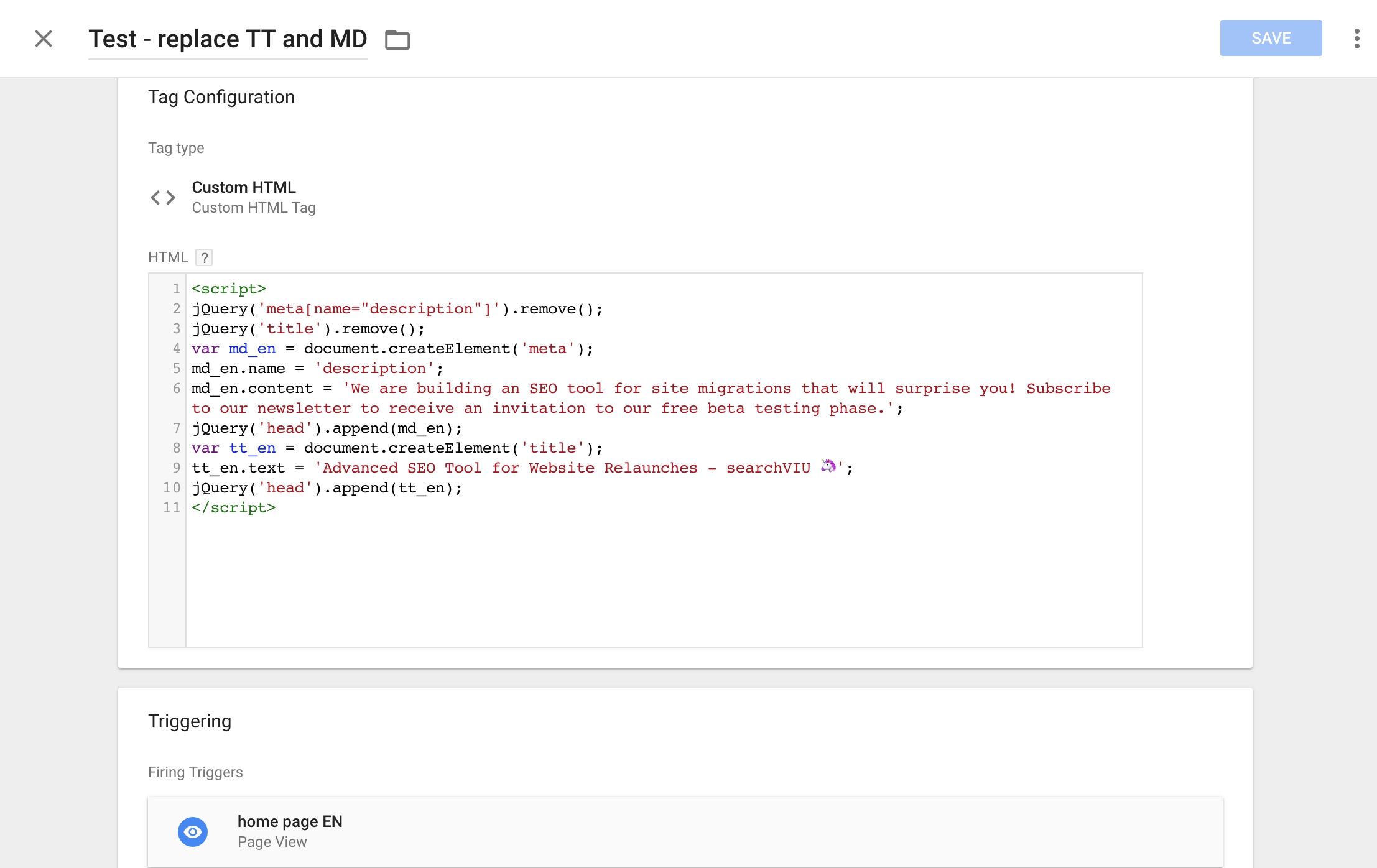
Note that for the title tag, we only changed the capitalisation, while in the meta description, we replaced a couple of words.
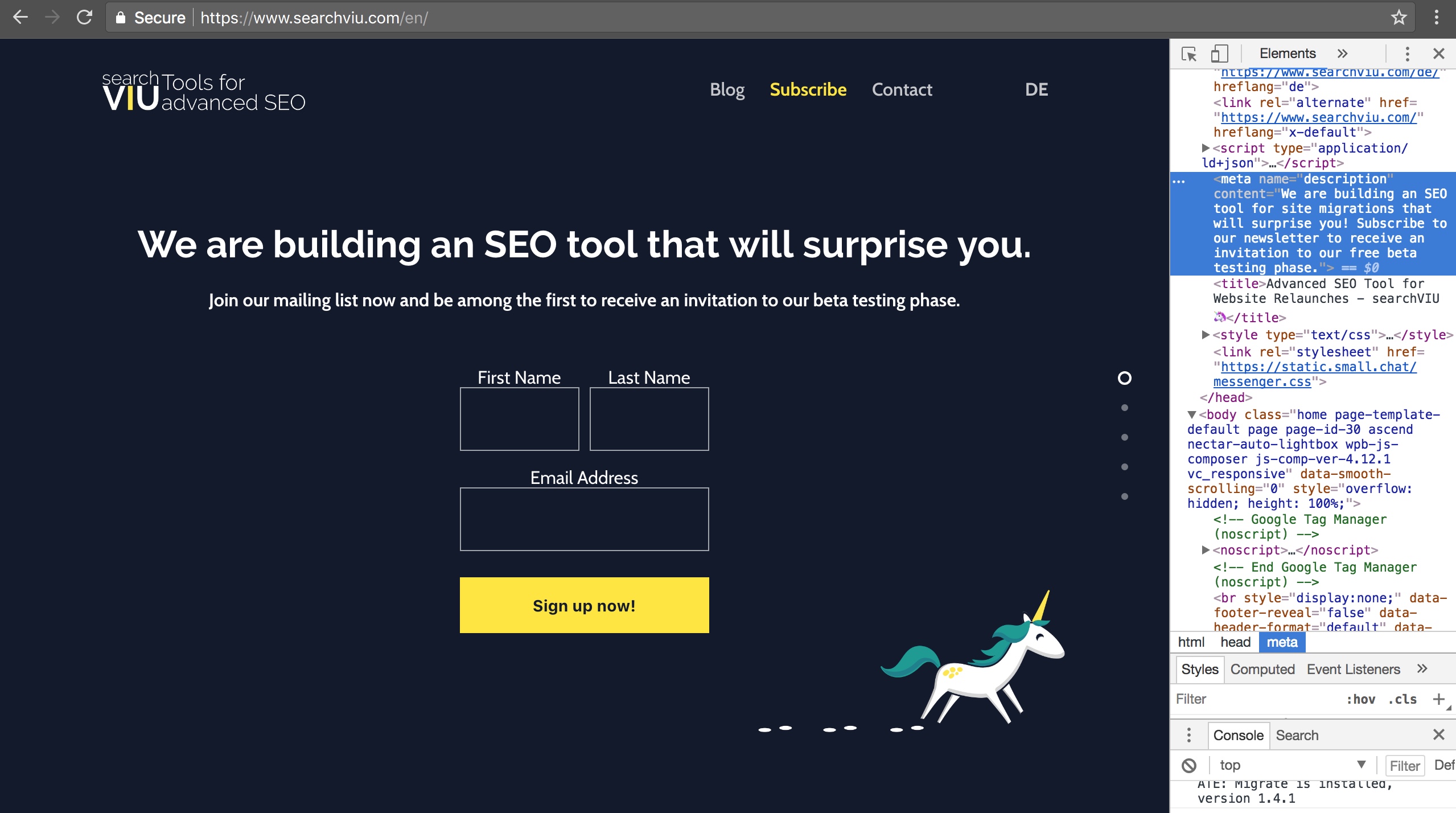
Now, the original title tag and meta description still show in the HTML source document, but if you check the rendered HTML with Chrome’s developer tools, you will see that GTM replaces them with the new version we have defined:
Eight days after we published this change in GTM, Google started showing the title tag and meta description we added with GTM, instead of the original data from the HTML source document, and has been showing them ever since:
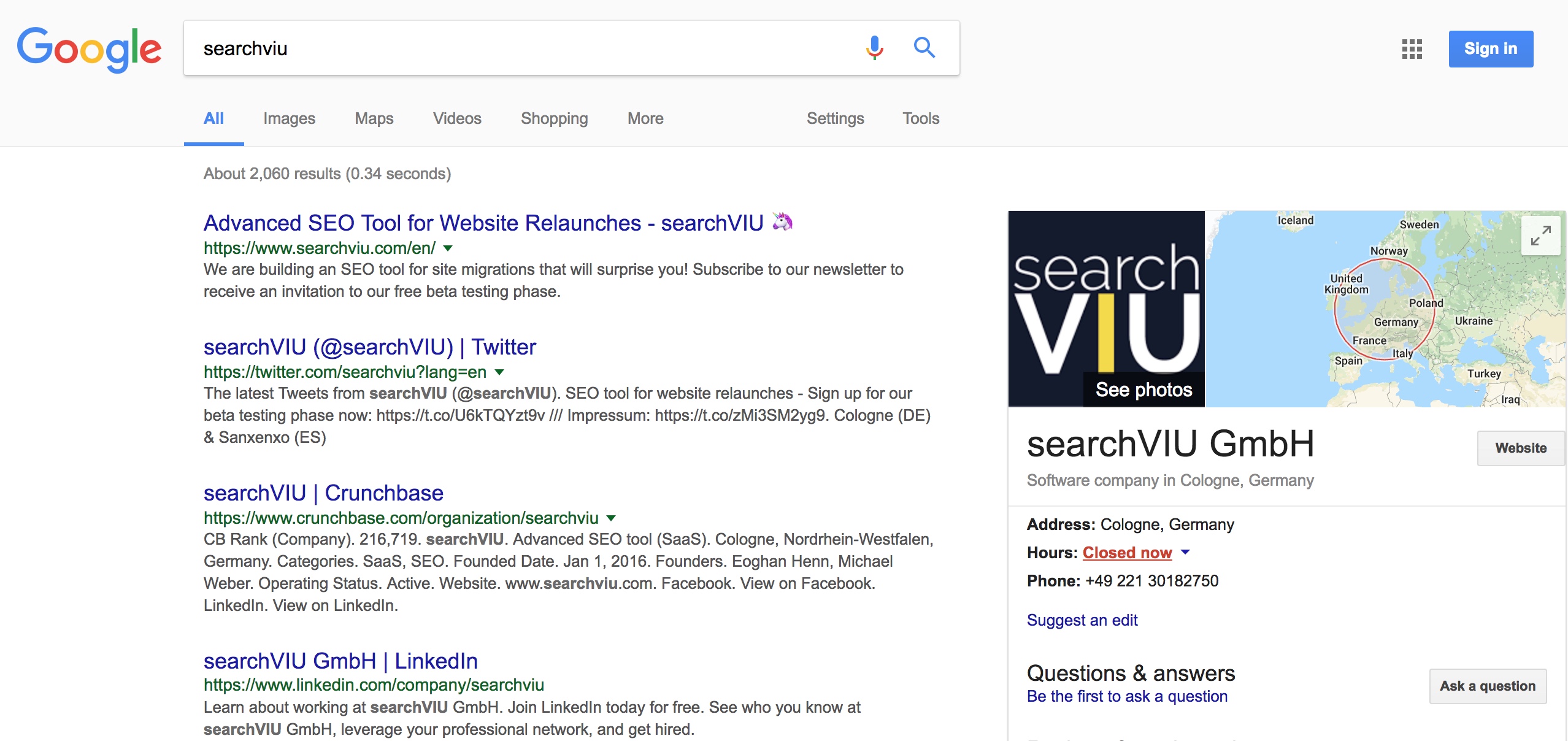
We were not really surprised by this outcome, as we had previously run an experiment that had suggested that Google uses the rendered HTML to interpret hreflang and ignores the HTML source document. So we kind of expected the same behaviour for title tags and meta descriptions.
The fact that the changes only showed up after eight days didn’t surprise us either, as Google renders pages less regularly than it crawls them. It would require more research to make a more solid statement about differences between crawling and rendering frequency, so this is just a side note.
Let us now have a look at some of the trickier things! Next stop: “noindex”.
De-indexing pages with “noindex” tags implemented via Google Tag Manager
While we were setting up these tests, we stumbled upon a few URLs from our domain that we didn’t want indexed:
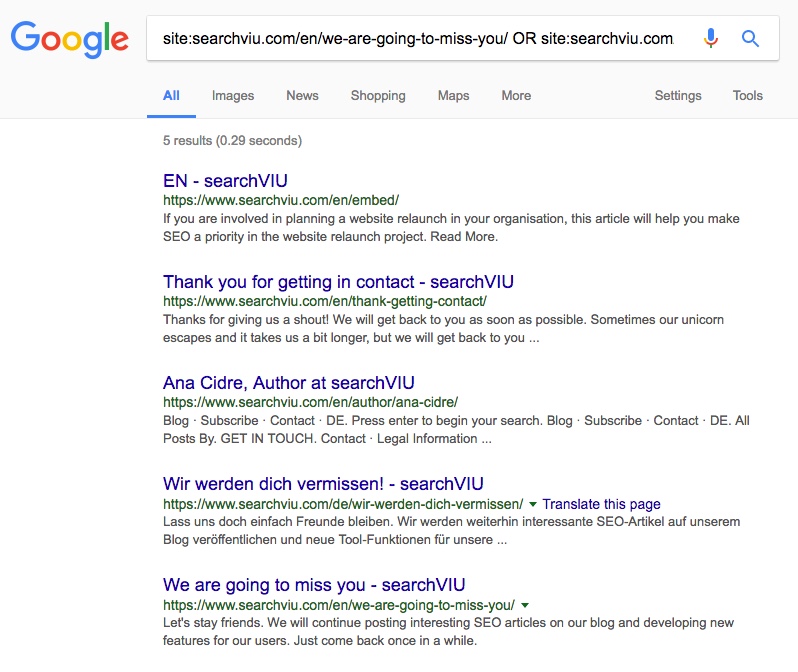
The following script, used in a Custom HTML tag in GTM, with a trigger that makes it execute on the pages we want de-indexed, adds a “noindex” meta tag to the pages in question:
And then we waited. And waited. And waited. And lost hope. Google was just not picking it up.
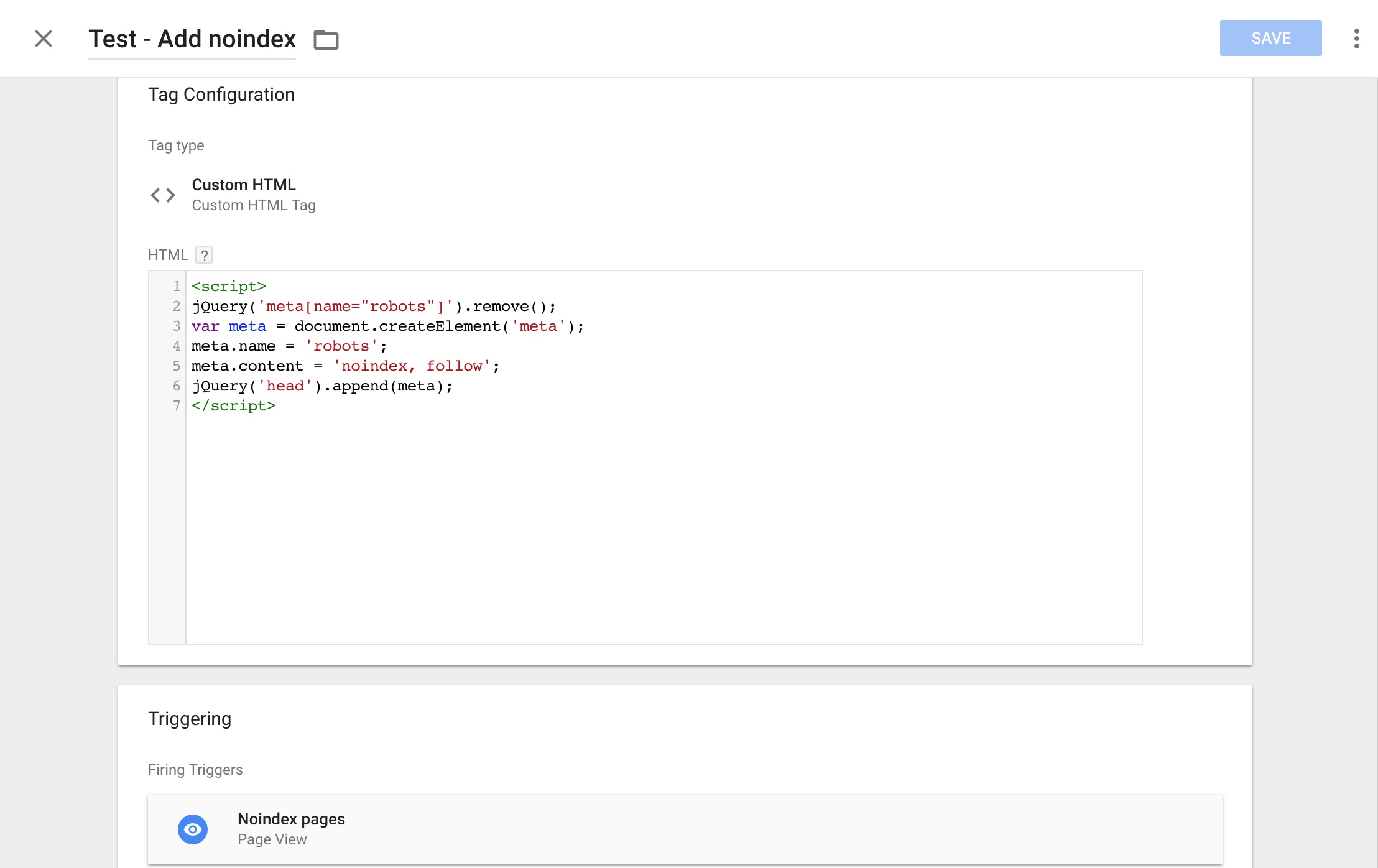
At this point, I have to admit that I am a sloppy researcher. I cannot tell you how long it took. Somewhere between 6 weeks and 3 months. But one day, Google decided to render the pages we wanted de-indexed and BOOM (all five pages successfully de-indexed):
Here’s the search query I used in the above screenshot, in case you want to check it out yourself:
So this also worked out just fine, but it took a lot longer than the changes to the title tag and meta description. Our theory right now is that less important pages get rendered even less frequently. But as I said above, we do need more research on the differences between crawling and rendering frequency before we can come to any solid conclusions about the topic.
Let’s see if the same thing works with canonical tags.
Adding canonical tags with Google Tag Manager
Canonical tags are tricky, because no matter how you implement them, Google often just decides to ignore canonical tags if there are other signals that are in conflict with them. So we needed to find an opportunity for a canonical tag that we were pretty sure Google would not ignore.
One of the most important requirements for the correct use of canonical tags is that the entire content of the page that has the canonical tag be included on the page the canonical tag is pointing to. For this reason, we chose to set a canonical tag from my author page to the main blog page, as the entire content of the former is available on the latter.
Here’s how to set this up in GTM:
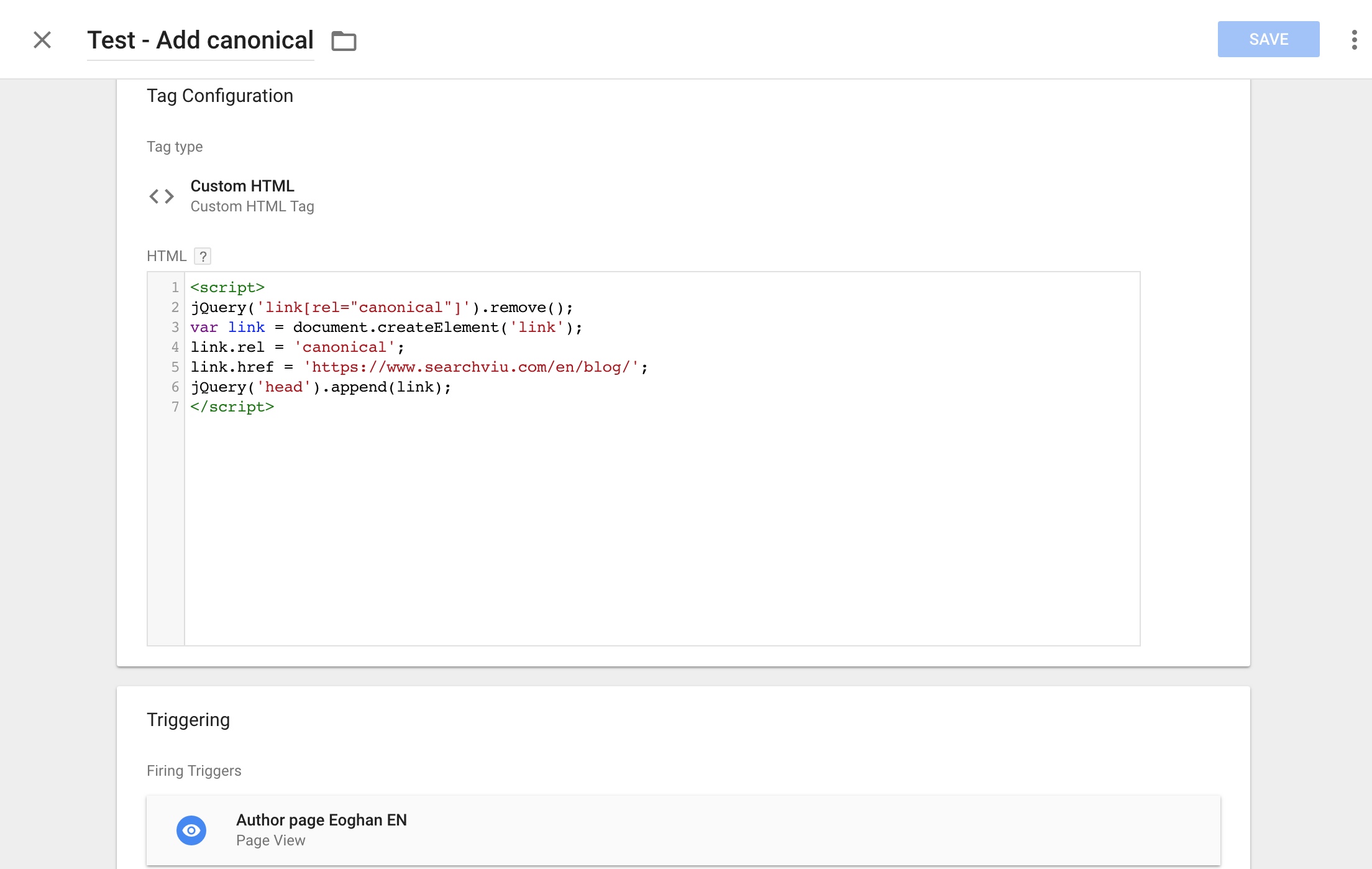
To make a long story short: This worked out just fine, but it took just as long as the “noindex” change.
Here’s the search result for the search query “eoghan henn searchviu” before we added the canonical tag with GTM:

And here’s the current result. The page has disappeared (and, as a matter of fact, the ranking has been lost – just another interesting side note):

So Google does respect canonical tags added with Google Tag Manager (if they’re used in the right context).
I know you’re mainly here for the info about links added with JavaScript, so let’s have a look at this now.
Does Google follow internal links added with Google Tag Manager?
One thing that we were really curious about when setting up this test was whether Google would crawl internal links that couldn’t be found in the HTML source document, but were added with JavaScript, using Google Tag Manager. So we set up the following little experiment.
First of all, we created two identical pages on our WordPress website, one that we would link to internally with a link added via GTM, and another one that we would not link to internally:
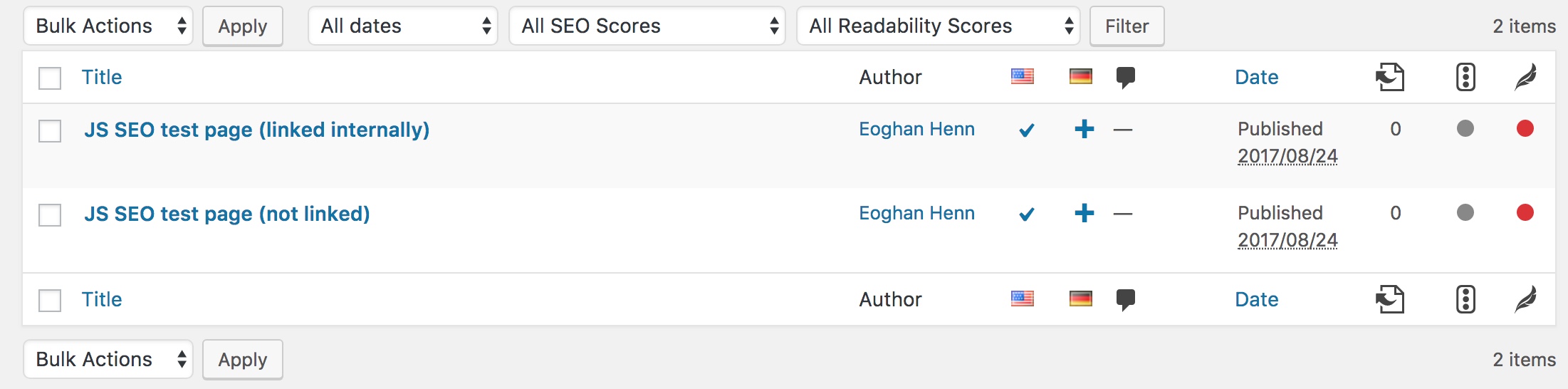
Why did we set up the second page? Well, if the first page gets indexed, we have to make sure it’s because of the internal link we injected, and not due to something else. We did make sure that the page wouldn’t appear in any sitemaps and that there weren’t any pings or other background mechanisms when we published it. But to be on the safe side, we decided to create the second page as a control page. The test result can only be positive if the first page is indexed and the second page isn’t.
Maybe I’m not such a sloppy researcher after all…
So let’s have a quick look at how we set this up in GTM. We picked a pretty unimportant page from our website, looked for a link that nobody would ever click on (hopefully) and used the following script in GTM to replace the target URL of the link with the URL of the first of our two test pages:
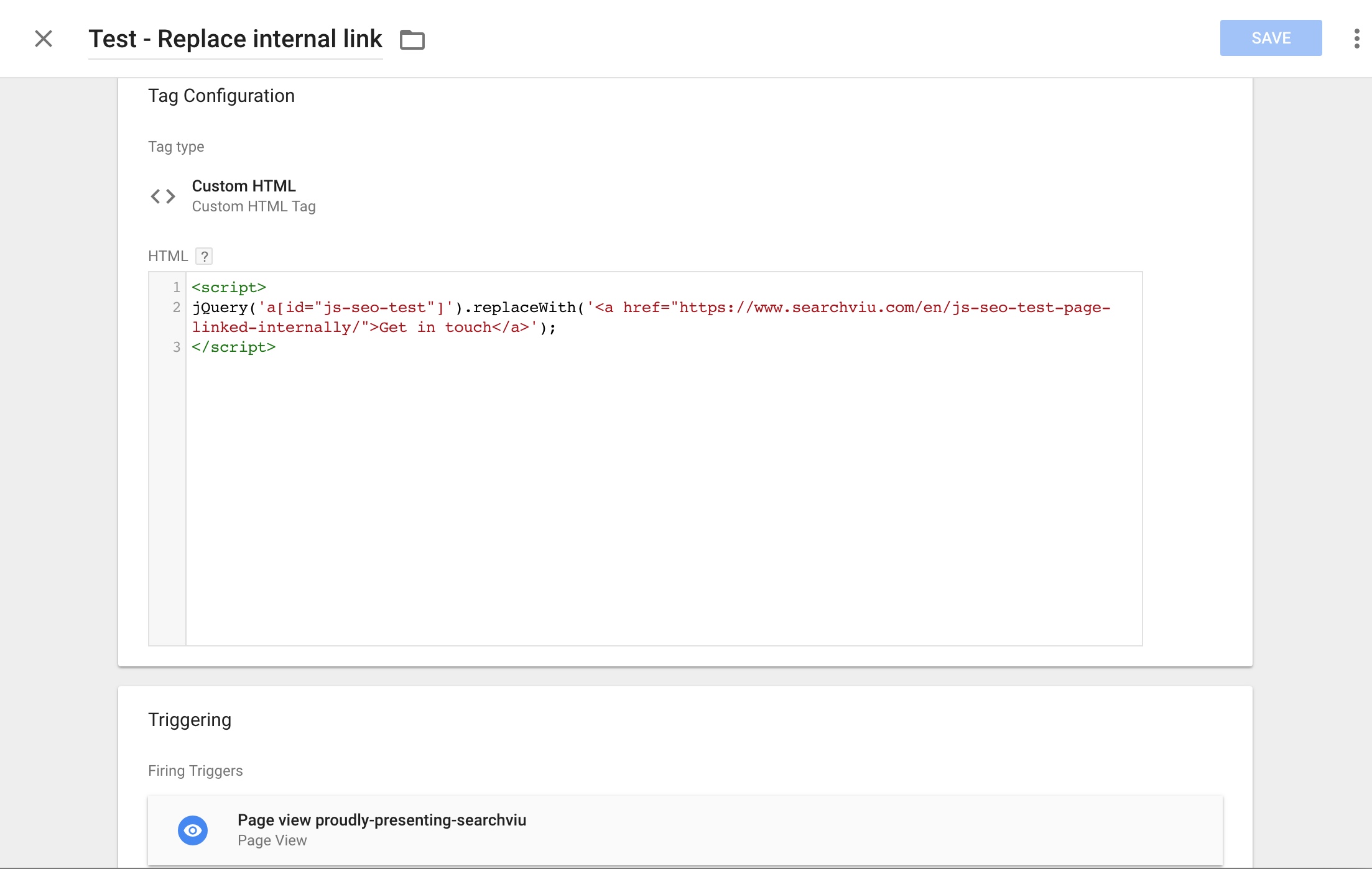
Here’s the result. The page that was only linked via a link injected with GTM was indexed, while the control page wasn’t. This, like the previous changes, took a very long time until it showed (roughly two months):
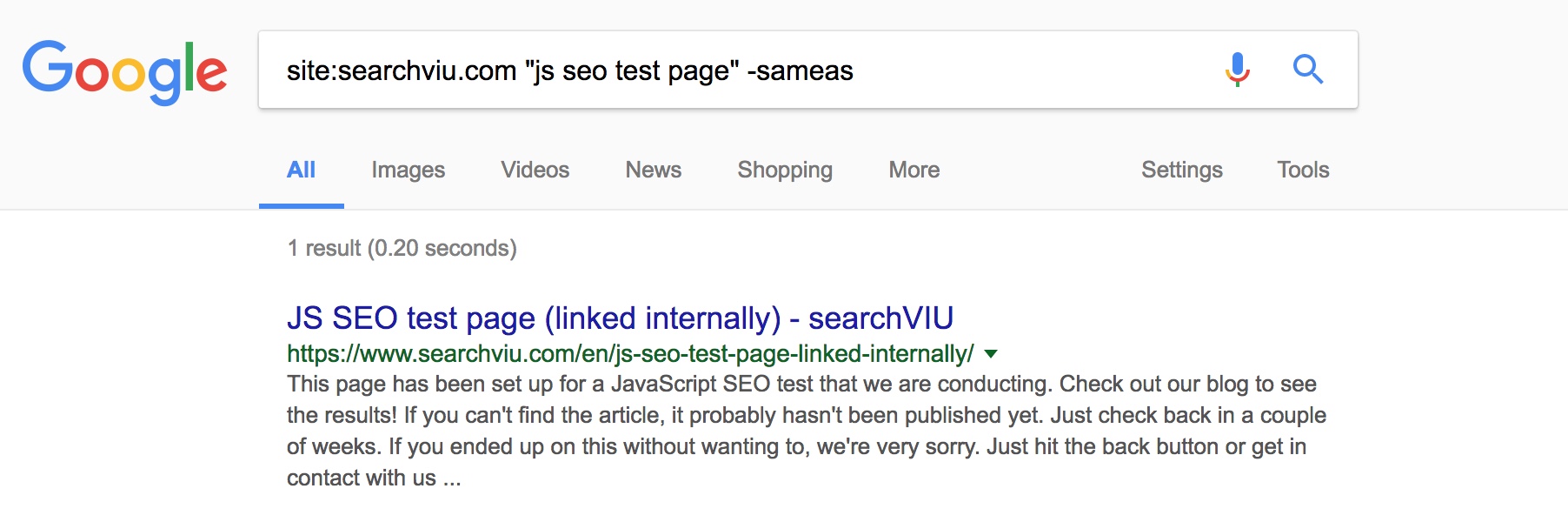
If you’re wondering about the -sameas part in the search query above, please read the next bit of this article. We created another test page that we only linked via JSON-LD injected with GTM to see how Google handles this kind of situation.
Does Google index URLs that are only included in JSON-LD scripts added with Google Tag Manager?
If you know me, you probably know that I’m really into implementing structured data (schema.org) in the JSON-LD format with Google Tag Manager. Also, I had previously noticed that URLs from one domain that were included in JSON-LD scripts on another domain showed up as external links to the first domain in Google Search Console. Google does some weird things with the information it finds in structured data, so I wanted to know more.
We decided to create another test page like the ones described in the internal link test above, but this time we would only include the URL in a JSON-LD script, and nowhere else. This is how to set it up in Google Tag Manager:
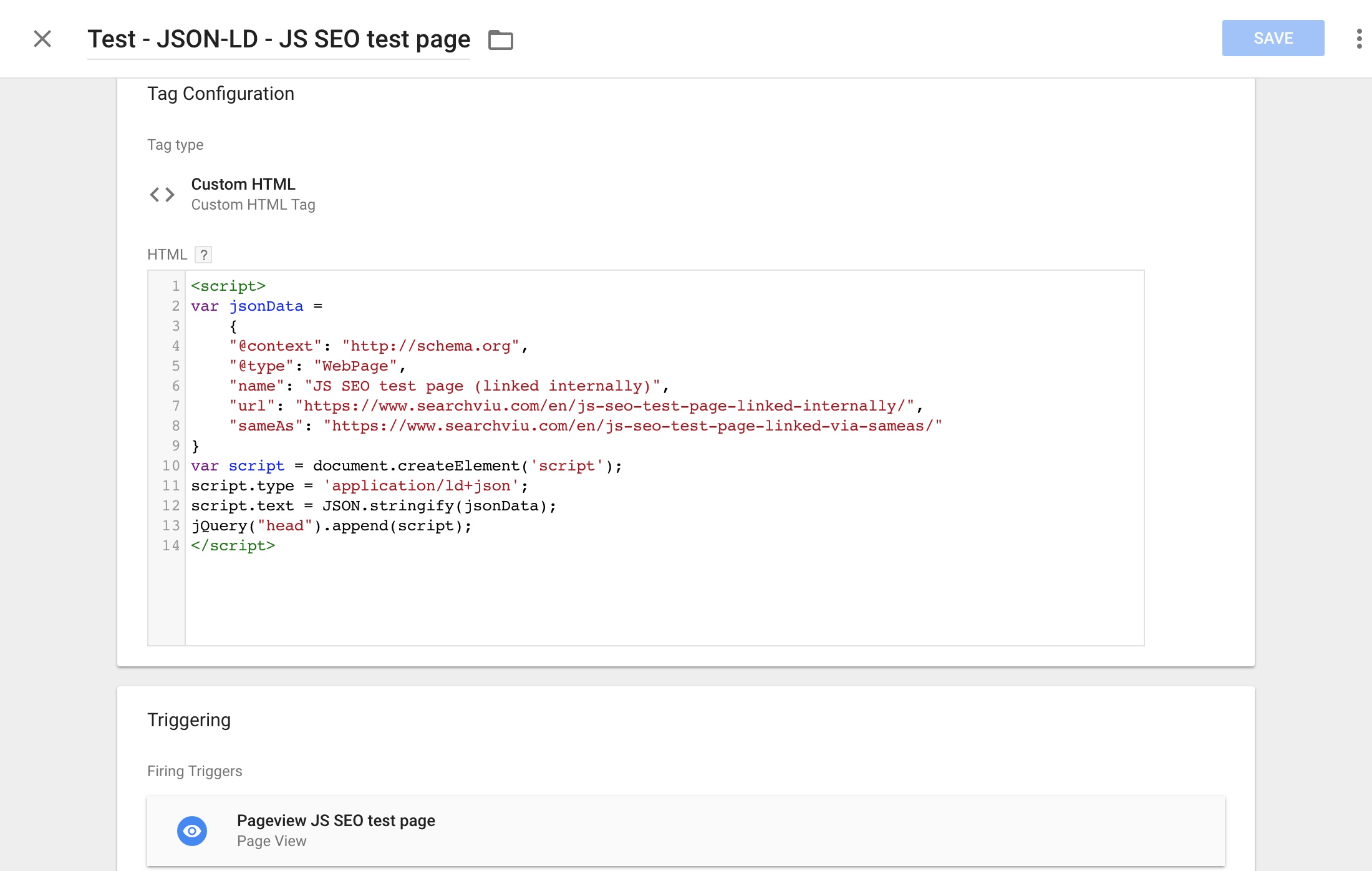
I guess that at this stage it doesn’t come as a surprise that this also worked. Google indexed the test page that was only linked via a JSON-LD script on the first test page:
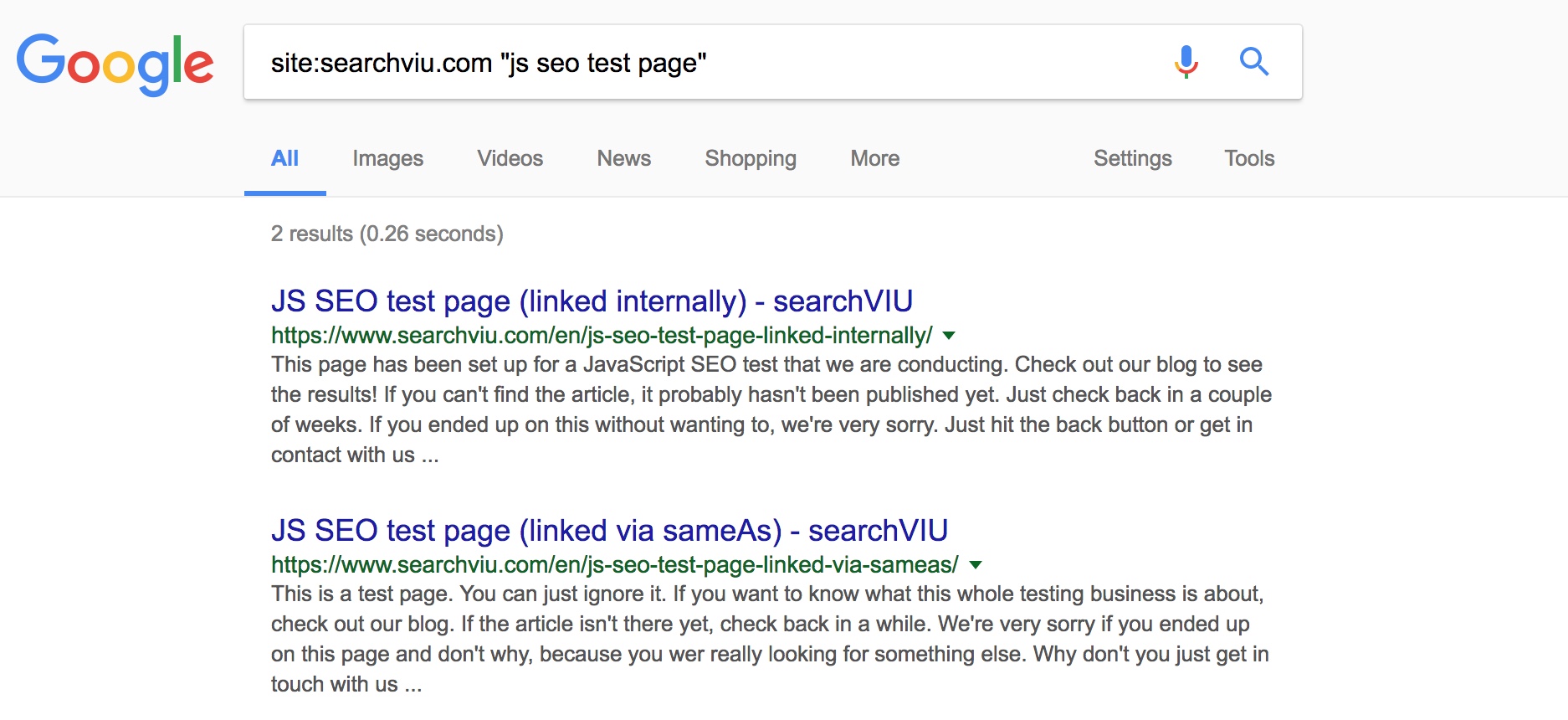
So JSON-LD scripts are another data source that Google uses for URL discovery purposes.
Conclusions: You can add everything with GTM, but it might take a while until the changes start showing.
The results of these tests have shown that Google will process and use title tags, meta descriptions, “noindex” tags and canonical tags added or modified with Google Tag Manager. The HTML source document is ignored and only the rendered HTML is considered.
Furthermore, internal links can be added with Google Tag Manager and Google will index the URLs that are linked this way. Even URLs that are only included in JSON-LD scripts added with Google Tag Manager will be indexed.
Unfortunately, this experiment wasn’t really designed to measure how long it takes for the changes to show in Google’s result. We didn’t set up a monitoring to check the results regularly. We do know that the changes to the title tag and meta description of the home page showed after eight days. All other changes took roughly two months until they showed.
It seems obvious that Google renders pages less frequently and crawls their HTML source documents more regularly. Further research on the differences between crawl and rendering frequency would be very valuable.
Former JavaScript SEO tests that didn’t take these huge delays into account might have had negative results because the tests didn’t run long enough, especially if they were conducted on pages that were only set up for the purpose of the experiment. It seems that important pages (like our home page in the case described above) are rendered more frequently than less important ones (like all of the other pages we did tests on that took roughly two months to show results).
We hope that you found our little JavaScript SEO experiment useful and that many others will set up similar tests, so that the entire SEO industry can learn more about how Google deals with pages that rely on JavaScript. Any questions or remarks? Just drop us a comment!
How nice to find this post and experiment!
I’m just having this problem. I’ve implemented Title and Description with Google Tag Manager but Google still takes the HTML.
I’ll wait a few more days. Thanks a lot for sharing this information!
Thanks for your comment, Jairo! I hope it all works out for you.
Hi Eoghan Henn, great article.
Now i have implemented a canonical tag by GTM, but Google does not seem to like it.
A Google bot has visited my site, but did not pick up my canonical tag.
The problem could be that there is a existing self-refering canonical tag already on the site. I remove that with jQuery(‘link[rel=”canonical”]’).remove(); and then implement my new canonical.
But Google seems to be reading only the old one.
Have you tested this setup or know if it should work?
thanks!!
Hi Hans,
Thank you for your interesting question. In general, if you remove the old canonical tag with jQuery and add a new one, Google should use the new one as soon it has rendered the page.
See this post for more details too: https://www.searchviu.com/en/javascript-canonical-tags/
In your case, what might have happened is that Googlebot visited your page but only fetched the source HTML without rendering the page. If you send me more details, I’ll be happy to have a look.
Super Post!
I have implemented this myself and discovered that it can be hard to index those meta tags in websites that rely heavily on JavaScript. Google might decide or not to run all the JS in your webpage. In that case, it might return your JavaScript injected Meta Title once, and decide to use the server-side originial Meta Title the next time.
I’ve had the result where Google decided not to use either one and choose their own title instead.
I think it would be good to use JavaScript instead of jQuery like Google’s own solution. I have not made any test whether one is better that the other but it jsut make sense that the JavaScript code will be read faster than the one with jQuery.
Like this:
var metaTag = document.querySelector(‘meta[name=”description”]’);
metaTag.setAttribute(‘content’, ‘Your Meta Description’);
Hi Eoghan, I am getting an error with any JS I try to inject via the steps above. The custom html triggers okay bet when I look at the tag in preview mode it is replacing some of the JS with unicode characters and is not appearing within the head. For example ‘meta[name=”description”]’ becomes ‘meta[name\x3d”description”]\’. DO you have any suggestions as to why this is happening to me?
Hi Carl,
Thank you very much for your comment. Scripts are often shown with some characters replaced in the GTM preview mode (I don’t know why, but it happens a lot), so this is probably not related to the problem that is causing your tag to not show in the head. Could you please send me some more details (screenshots etc.) via email, so that I can have a closer look?
Hi, great article.
Only a consideration: your noindex SEO if you check source code you see noindex meta by Yoast:
view-source:https://www.searchviu.com/en/we-are-going-to-miss-you/
Your script remove the original meta and replace with the same instruction.
So, are you sure that the noindex instruction is about your javascript? I think is the original meta the noindex reason
Hi Matteo,
Thank you very much for your comment. Your observations are absolutely correct, but the website isn’t in the same state as it was when we conducted the tests more than a year ago. At the time of the experiment, there was no “noindex” available in the source code and it was only added with GTM.